News
Splice Machine Makes Waves as 'Only Hadoop RDBMS'
- By David Ramel
- August 8, 2014
Splice Machine Inc. is getting a lot of attention as it seeks to carve out a niche for itself in the exploding Big Data analytics arena by combining the advantages of traditional Relational Database Management System (RDBMS) technology with the scale-out capabilities associated with NoSQL databases.
The company in May launched a public beta of what it claims is "the only Hadoop RDBMS" on the market. On Wednesday, the San Francisco-based start-up announced a $3 million financing extension. Along the way, it has picked up official accolades from organizations such as Red Herring, AlwaysOn and Gartner.
Built on top of the open source Java-based Apache Derby relational database and Hbase -- an open source, distributed non-relational database, working with Hadoop -- the Splice Machine database is ACID-compliant and is used to power online analytical processing (OLAP) and online transaction processing (OLTP) workloads.
"If I were to sit down and think of a full-scale environment, it has to have a file system, it has to have an OLTP engine and it has to have a query engine," said independent analyst Dr. Robin Bloor in a webinar with Splice Machine co-founder John Leach on Tuesday. "You might need to have other things, but it has to have all of those. And here we have Splice Machine, and I think they're on their own in being able to provide the OLTP engine with a nice mixed-workload capability."
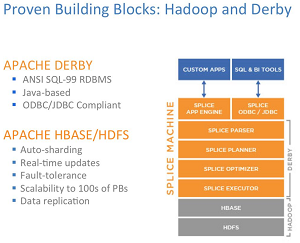 [Click on image for larger view.]
How Splice Machine technology works with other components.
[Click on image for larger view.]
How Splice Machine technology works with other components.
(source: Splice Machine)
Bloor and Eric Kavanagh, CEO of The Bloor Group, questioned Leach about Splice machine's technology and approach. Kavanagh said it appeared the company was combining parts of different technologies to provide the best functionality of several worlds, handling key problems on the read side of database operations. Leach noted that the company has actually taken out patents on optimization techniques for different technologies, but basically agreed with the simplified capsulation of the company's technology approach.
An audience member observed that the technology sounded great for real-time operational data store needs, to handle transactions while providing near-real-time reporting. Leach agreed.
"Our goal is, when you look at environments, the databases that run applications and they run operational data stores generally are Oracle, DB2, those types of databases. And our goal with this is to provide an affordable, scale-out solution for that workload. Maybe some OLTP, definitely things where you're performing updates, deletes and you need basic data management functionality. And then, for every system, there's always operational reporting needs.
"So if you think about it, we don't take the view that there's an OLTP world and an OLAP world," Leach continued. "We take the view that applications somewhere fit in that continuum, and to be honest I think that's Oracle's approach and why they've been so successful. They realize that you have to be able to support both workloads." He said it may not be the most optimal workload solution in either case but really fits for most applications.
Leach noted that his company partners with major Hadoop distributors such as Hortonworks Inc., Cloudera Inc. and MapR Technologies Inc. While Splice Machine has run tests on plain-vanilla Hadoop, Leach said most customers have already implemented or picked one or several distributions and the company works with them on their individual scenarios, especially when they run into scale-out problems with their existing databases.
In fact, he said, when asked by Bloor about how many customers were using data lakes or insisted on ACID compliance, Leach said many calls came in from people needing help with "hair-on-fire" database issues and may not have even been focused on Hadoop.
As far as using operational data lakes -- still a pretty new concept -- Leach said, "At first I think people think of Hadoop, like you said earlier, as a database, not as a file system. Initially they start throwing files there and they do a POC [proof of concept] and they think, 'oh, I can throw some files out on the file system, manage those files and run query engines, whether it's Hive or other products, Impala, Drill, etc. on top of it.' And then as they get more sophisticated, as they really try to make Hadoop that refinement layer, that's generally where people start to say, 'Hey, wait a minute, I still need to dedupe data, I need to incrementally update data. I can't shut down the environment when doing an update. There's things going on concurrently. I need many users to connect to this environment.' And when they start to get sophisticated, that's where we started to have some calls."
The analysts discussed how Big Data analytics and the Hadoop ecosystem were evolving and becoming more sophisticated while at the same time easier to use and more accessible, with the addition of technologies such as the YARN resource manager that can be used in place of MapReduce.
Splice Machine, Leach said, provides another level of sophistication going beyond the days of pushing around read-only flat files to systems that can handle a lot of concurrency, organize data and manage it without duplication or violating restraints while at the same time maintaining referential integrity.
"If you think of Hadoop right now," Leach said, "it's similar to the mainframe days where it was file-based processing. This is just going the next step to make it highly concurrent."
Kavanagh and Bloor agreed that Splice Machines was doing as good a job as any vendor out there, if not better, in advancing the technology in the niche it's carving out for itself.
Bloor said the technology was one of the pieces of the Big Data puzzle coming into place. "I look at this and I just think it's got a place. Now how big of a place, it's got, you just wait to see what the world does to see how big a place it's got. But I think this has got a place."
About the Author
David Ramel is an editor and writer for Converge360.