News
BI-on-Hadoop Benchmark Reveals Analytical Engine 'Sweet Spots'
- By David Ramel
- October 24, 2016
BI-on-Hadoop specialist AtScale Inc.'s recent analytical engine benchmark study concludes that organizations will probably need to use multiple such engines for a successful implementation able to handle varied workloads.
The company researched four analytics engines in the open source world -- Hive, Impala, Presto and Spark SQL -- in order to publish its new reference performance study: The Business Intelligence for Hadoop Benchmark Q4 2016.
The good news is the company found continuing innovation across all products, resulting in 2x to 4x performance gains in just the six months since the first edition of the study was conducted. The not-so-good news is that none is likely to provide one sole solution for all the varied Big Data analytical workloads.
Depending upon the type of query and other factors, "enterprises will find that each engine has its own 'sweet spot,' " AtScale said.
"There is no single 'best engine,'" the study concluded. "Presto, Hive, Impala and Spark SQL were all able to effectively complete a range of queries on over 6 billion rows of data. The 'winning' engine for each of our benchmark queries was dependent on the query characteristics (join size, selectivity, group-bys)."
For example, one "sweet spot" for Presto and Hive is handling a large number of concurrent dashboard queries. "Production enterprise BI user-bases may be on the order of 100s or 1,000s of users," AtScale said. "As such, support for concurrent query workloads is critical. Our benchmarks showed that Presto and Impala performed best -- that is, showed the least query degradation -- as concurrent query workload increased. Presto, new to this edition of the benchmark, showed the best results in our user concurrency testing."
 [Click on image for larger view.]
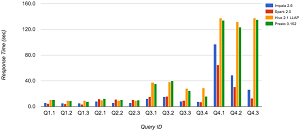
Benchmark Query Results for Large Tables (source: AtScale)
[Click on image for larger view.]
Benchmark Query Results for Large Tables (source: AtScale)
For querying large data sets, the study said: "Consistent with the findings in the First Edition of the BI on Hadoop Benchmarks, Spark SQL and Impala tend to be faster than Hive. For many queries, the performance difference between Impala and Spark SQL is relatively small. Presto 0.152, a newcomer to the Second Edition of the BI on Hadoop Benchmarks, shows a performance profile that is very similar to that of Hive 2.1."
On the smaller side of things, Impala and Spark SQL perform better, the company said. "Impala and Spark SQL continue to shine for small data queries (queries against the AtScale Adaptive Cache). New in this edition, the latest release of Hive LLAP (Live Long and Process) shows suitable 'small data' query response times. Presto also shows promise on small, interactive queries."
The Presto analysis was added to the AtScale project after the first edition was published in February.
AtScale said it conducted the study to reveal the strengths and weaknesses of the industry’s most popular analytical engines, focusing on three criteria: how they perform when processing large amounts -- billions or trillions of rows -- of data; how fast they are on smaller, interactive queries; and how stable they are for many users.
After discovering that all four engines perform well for general use cases and workloads, AtScale concluded that "A successful BI-on-Hadoop architecture will likely require more than one SQL on Hadoop engine. Each engine has its strengths: Presto's and Impala's concurrency scaling support for quick metric queries, Spark SQL's handling of large joins, Hive's and Impala's consistency across multiple query types. Enterprises might consider leveraging different engines for different query patterns."
About the Author
David Ramel is an editor and writer at Converge 360.