News
DataTorrent Announces Tools for Hadoop Ingestion, Data Processing
- By David Ramel
- August 3, 2015
DataTorrent Inc. unveiled a product to manage the ingestion of data into Hadoop systems -- aiming to simplify a process that it says traditionally relies on a lot of moving parts and multiple tools -- and announced the open source project underlying its Big Data processing technology is now available on GitHub.
The new ingestion tool, dtIngest, which the company said "simplifies the collection, aggregation and movement of large amounts of data to and from Hadoop," is free for unlimited use by organizations.
Company exec Himanshu Bari said organizations typically have to rely on one-off ingestion tools to handle the wide variety of data sources needing to be pumped into a Hadoop platform for Big Data analytics. "These one-off jobs copy files using FTP and NFS mounts or try to use standalone tools like 'DistCp' to move data in and out of Hadoop," Bari said in a blog post last Thursday. "Since these jobs stitch together multiple tools, they encounter several problems around manageability, failure recovery and ability to scale to handle data skews."
DataTorrent said these problems are being solved by its single solution that provides point-and-click simplicity for moving data into and out of Hadoop. A key advantage of the company's tool, Bari said, was complete fault tolerance, which allows it to resume operations where it left off in the event of a system failure, which he said the DistCp approach, for one example, can't do. DistCp, standing for distributed copy, is an Apache Hadoop tool for large inter/intra-cluster copying.
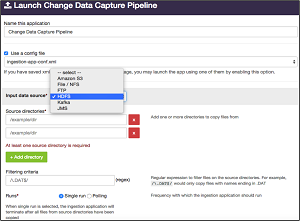 [Click on image for larger view.]
Point-and-Click Data Capture (source: DataTorrent Inc.)
[Click on image for larger view.]
Point-and-Click Data Capture (source: DataTorrent Inc.)
The Santa Clara, Calif.-based 2012 startup said unique features provided by dtIngest include:
- Handling of batch and stream data, supporting the movement of data between NFS, (S)FTP, Hadoop Distributed File System (HDFS), AWS S3n, Kafka and Java Messaging Service (JMS) with one platform to exchange data across multiple endpoints.
- Configurable automatic compaction of small files into large files during ingest into HDFS, to help prevent running out of HDFS namenode namespace.
- Secure and efficient data movement through compression and encryption during ingestion, certified for Kerberos-enabled secure Hadoop clusters.
- Compatibility with any Hadoop 2.0 cluster, certified to run across all major Hadoop distributions in physical, virtual or in-the-cloud deployments.
The dtIngest tool is a native YARN application built on top of Project Apex, the Apache 2.0 open source unified batch and stream processing engine that underlies the company's commercial offering, DataTorrent RTS 3.
Along with unveiling dtIngest, DataTorrent announced the availability of a Project Apex GitHub repository. The company offers a Community Edition of DataTorrent RTS 3 based on Project Apex, along with a Standard Edition and an Enterprise Edition with more operational management, development and data visualization functionality. The new ingestion tool is available as an application package with all DataTorrent RTS 3 editions.
"Getting data in and out of Hadoop is a challenge for most enterprises, and yet still largely neglected by current solutions," the company quoted 451 Research analyst Jason Stamper as saying. "No existing tool handles all the requirements demanded for Hadoop ingestion. Without proper ingestion and data management, Hadoop data analysis becomes much more troublesome. DataTorrent dtIngest delivers an enterprise-grade user experience and performance."
About the Author
David Ramel is an editor and writer at Converge 360.