News
Hadoop Creator Yahoo Finds It's Not Enough, Turns to Druid
- By David Ramel
- July 30, 2015
This Hadoop thing started by Yahoo 10 years ago seems to be catching on, but it lacks certain functionality, so the Web giant has moved on in its never-ending quest for more efficient Big Data processing. Say hello to Druid.
"While Hadoop still solves many critical problems in our business, as our needs have grown, we've come to realize that Hadoop is not the end-all, be-all solution to the entirety of our data problems," said a post on the Yahoo Engineering blog site this week.
Chief among those data problems is the need for interactive analytics, which isn't a strong point of the oft-maligned MapReduce framework, an original component of the Hadoop ecosystem.
"While MapReduce is a great general solution for almost every distributed computing problem, it is not particularly optimized for certain things," Yahoo said. "Specifically, MapReduce-style queries are very slow. As our data volumes grew, we faced increasing demand to make our data more accessible, both to internal users and our customers. Not all of our end users were back-end analysts, and many had no prior experience with traditional analytic tools, so we wanted to build simple, interactive data applications that anyone could use to derive insights from their data."
To that end, the company tried a bunch of options: Apache Hive, a data warehouse infrastructure running on Hadoop; traditional relational databases; key/value stores; the incredibly popular Apache Spark engine (with in-memory speed improvements) and its complementary Apache Shark data warehouse; Impala, a distributed SQL query engine; and others.
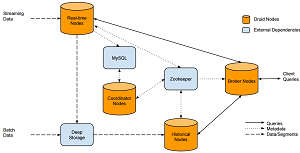 [Click on image for larger view.]
Flowing Data through a Druid Cluster (source: Druid.io)
[Click on image for larger view.]
Flowing Data through a Druid Cluster (source: Druid.io)
"The solutions each have their strengths, but none of them seemed to support the full set of requirements that we had," Yahoo said, including:
- Adhoc slice-n-dice.
- Scaling to tens of billions of events a day.
- Ingesting data in real-time.
Then came Druid.
Yet another open source project with an Apache license, Druid was originally authored by Eric Tschetter and Fangjin Yang at Metamarkets in 2011.
"Druid is an open-source analytics data store designed for business intelligence (OLAP) queries on event data," the project's site states. "Druid provides low latency (real-time) data ingestion, flexible data exploration, and fast data aggregation. Existing Druid deployments have scaled to trillions of events and petabytes of data. Druid is best used to power analytic dashboards and applications."
Which is exactly what Yahoo is using it for.
"This feature set has allowed Druid to find a home in a number of areas in and around Yahoo, from executive-level dashboards to customer-facing analytics and even some analytically-powered products," the company said.
Besides Yahoo, Druid is powering data systems at many other major companies, including Cisco, eBay, Netflix and Paypal. It's stewarded by the Druid Community, which points out Druid-powered production clusters have scaled to:
- More than 3 trillion events/month.
- More than 1 million events per second through real-time ingestion.
- More than 100 PB of raw data.
- More than 30 trillion events.
- Hundreds of queries per second for applications used by thousands of users.
- Tens of thousands of cores.
Druid was influenced by already existing analytic data store solutions and search infrastructure, with a special nod to Google's BigQuery, Dremel and PowerDrill technologies.
Even though Yahoo described Druid as "a column-oriented, distributed, streaming analytics database designed for OLAP queries," the Druid site's FAQ takes pains to note that it isn't a NoSQL database, and -- with limited editing/deleting capabilities -- "it is best not thought of as a database of any kind."
The Druid "About" page includes links that explain how the project compares to other technologies, with separate entries for Hive/Impala/Shark/Presto, Amazon Redshift, Vertica, Cassandra, Hadoop, Spark and Elasticsearch.
Its external dependencies include a "deep storage" infrastructure needed to make sure data is available for ingestion. This deep storage can be Amazon S3, Hadoop Distributed File System (HDFS), Microsoft Azure Storage or any such file system that is sharable and mountable. It also requires metadata storage -- such as MySQL or Postgres databases -- and Apache ZooKeeper, "a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services."
Yahoo noted that Druid is a complement to -- not a replacement of -- Hadoop. "To this day, we still run some of the world's largest Hadoop clusters, and use it for everything from clickstream analysis to image processing and business intelligence analytics," the company said. "Additionally, our developers continue to act as good open source citizens, and contribute all our Hadoop developments back to the community."
The Web giant said it's also working with the Druid Community to further that project's development. That community is active on a Google Groups for users and developers and on IRC (#druid-dev on irc.freenode.net). Contributor guidelines are available here.
About the Author
David Ramel is an editor and writer at Converge 360.